[Regex] Regex Cheatsheet and Practice
Một vài note cho regex trong những ngày cuối năm 2019 nào!!!!
1. Cheatsheet
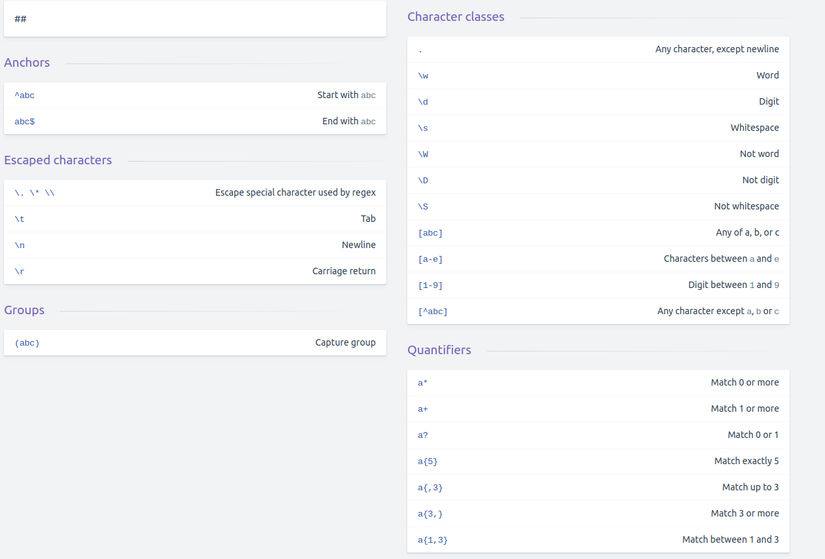
Nguồn: https://devhints.io/regexp.
Và

Nguồn: http://regextutorials.com/intro.html?Basic%20symbols
2. Một vài note cho regex
Regex là công cụ mạnh mẽ chuyên xử lý chuỗi. Nó có thể:
- Kiểm tra, validate dữ liệu: kiểm tra một câu có chứa hoặc không chứa một từ, cụm từ nào không, có đúng theo 1 biểu thức chính quy nữa không?
- Thay thế: thay thế chuỗi này bằng một chuỗi mới. Cái này khá hay và mạnh :D
- Lấy giá trị: lấy giá trị các chuỗi sau một biểu thức chính quy
2.1. Symbol repetition
Đúng như tên gọi của nó, các ký tự này đại diện cho các kí tự sau đó. Còn đại diện cho 1 hay 0, hay nhiều kí tự thì phụ thuộc vào bạn dùng kí tự nào nhé :D.
Các ký tự lặp lại như thế này gây ra khó hiểu cho tôi hồi mới đọc. Trong ví dụ giải thích sẽ nói về \*. Trùng 0 hoặc nhiều ở đây sẽ hiểu là trùng với kí tự trước nó. Ta xét ví dụ \d\d*:
\d: kí tự đầu tiên là số
\d* kí tự sau sẽ có 2 khả năng:
- Match 0: không có gì cả
- Match more: có và với điều kiện tất cả phải là số (more mà)
Do đó \d\d* là số với độ dài bất kỳ. Vậy nó khác gì với \d*
- Match 0: không có gì, kí tự trống. Thực tế là các kí tự đỏ đỏ ngăn cách mỗi ký tự (kí tự đỏ đỏ ở đây nhé :v https://regex101.com/)
- Match more: rõ ràng trước hợp trên không có thì sử dụng trường hợp này rồi. Nó cũng là số với độ dài bất kì.
Như vậy cả \d* và\d\d* đều là số có độ dài bất kì, \d* bắt cả kí tự rỗng và không nên sử dụng.
Theo tôi khi sử dụng các kí tự lặp lại có thể match 0 (\* và ?), không nên để kí tự trước nó đứngđộc lập 1 ký tự khác để tránh việc lấy phần match 0 (các kí tự không có gì).
- \d*, \d? => không nên vì nó lấy cả ký tự rỗng
- \d*minh, s?he => OK
2.2. Line and word breaks and spaces
^: bắt đầu 1 dòng$: kết thúc 1 dòng\b: đại diện cả bắt đầu và kết thúc 1 từ luônIn regular expressions, there are symbols that do not correspond to a character, but to a position. ^ and $ stand for start and end of line. While \b means a word boundary. Try using ^\w+ and \w+$ to match the first and last word in each line. \b\w and \w\b will match first and last letter in word. Finally, use \s to match any space symbols whatsoever.
Cái này dùng để xác định phạm vi bạn muốn sử dụng regex. Bạn muốn check cả câu thỏa mãn điều kiện hay tìm từng chuỗi một thỏa mãn.
Vậy ^[^abc]+$ và [^abc]+ khác nhau cái gì vậy?
^[^abc]+$: kiểm tra cả câu không chứa a,b,c? => trả về cả câu nếu phù hợp[^abc]+: kiểm tra các ký tự trong câu, trả về các kí tự không chứa abc
2.3. Grouping matches and replacing
Cái này cũng là cái khá hay trong regex.
Bạn có thể nhóm các phần trùng với nhau bằng cách đặt chúng trong dấu (). Sau đó bạn có thể tham chiếu đến các nhóm này bằng cách sử dụng \1,\2, etc. Ví dụ (\w)\1 trùng với 1 vài kí tự được lặp lại 2 lần (\1 lặp lại của \w vì được nhóm vào trong nhóm 1 mà)
Điểm quan trọng nhất là bạn có thể nhóm cho sự thay thế, tham chiếu chúng bởi số: $2, $1 … trong việc thay thế các biểu thức. Hãy thử thay thế format tên như dưới đây từ John Smith thành Smith,John bằng cách thay thế (\w+)\s(\w+) bằng $2,$1. Thật tuyệt. Nếu bạn muốn sử dụng dấu ngoặc đơn nhưng không tính là nhóm lại, sử dụng (?:expression)
2.4. Lookaheads
(?=) được gọi là lookaheads. abc(?=d) sẽ trùng abc chỉ nếu nó được theo sau bởi d (hiểu là kí tự ngay sau đó là d). Chú ý là d sẽ không trong giá trị trùng (giá trị thỏa mãn chỉ là abc, không phải abcd). Thử sử dụng\w+(?=\.) để trùng với các từ cuối cùng trong 1 câu.
abc(?!d) sẽ trùng với abc KHÔNG theo sau là d. Thử sử dụng \w+(?!\.)\b để trùng với tất cả các từ không phải là kí tự cuối cùng của 1 câu (kết thúc bằng dấu chấm).
Negative lookahead có thể check được cả chuỗi KHÔNG chứa chuỗi con nào đó :D. Ví dụ: use negative lookahead ‘?!’ to check that there is no word ‘chocolate’ ahead at every position between the start and end of line.
Hãy nhớ rằng các lookaheads cũng không nên đứng độc lập vì “Chú ý là d sẽ không trong giá trị trùng (giá trị thỏa mãn chỉ là abc, không phải abcd)”, nếu đứng độc lập nó bắt cả kí tự rỗng như match 0 đó. Do vậy bạn muốn bắt 1 kí tự không chứa abc thì không thể viết (?!abc)+ vì bản thân (?!abc) không đại diện kí tự gì. Nó cần phải có kí tự trước hoặc sau đi kèm như .(?!abc) hay (?!abc). và 2 cú pháp nay thực chất chỉ đại diện cho 1 kí tự (vì nhắc lần 2, hãy nhớ rằng giá trị lookahead không trong giá trị trùng)
3. Regex excercises
3.2. Bài toán lấy các năm trước 1990
Ý tưởng: kí tự đầu tiên là 1, kí tự tiếp theo từ 0-8, kí tự tiếp theo có 2 khả năng: nếu là 9 thì kí tự thứ 4 là 0, nếu là 0-8 thì kí tự tiếp theo là từ 0-9
=> Biểu thức regex: .*(1[0-9]([0-8][0-9]|90)\)).
Có thể rút gon [0-9]=>\d. ta có biểu thức.*(1\d([0-8]\d|90))\)
3.4. Grayscale colors
Bài toán sử dụng regex với sự thay thế.
Bài toán tìm các màu red, green and blue, các màu mà có mã lặp lại (12 hoặc 24 bit)
Ý tưởng:
- Dùng
\1,\2để dùng cho các kí tự lặp lại, nhóm với nhau bằng dấu() - Do 2 trường hợp 12 hoặc 24 bit nên dùng
{1,2}cho bài toán này
The solution is: #([0-9a-fA-F]{1,2})\1\1
3.6. Remove repeating words
Một bài toán nữa sử dụng regex cho sự thay thế chuỗi hiệu quả.
Bài toán sẽ là lọc các từ lặp lại trong câu sau:
It was a chilly November afternoon. I had just just consummated an unusually hearty dinner, of which the dyspeptic truffe formed not the least important item, and was sitting alone in the dining-room dining-room, with my feet upon the the fender, and at my elbow a small table which I had rolled up to the fire, and upon which were some apologies for dessert, with some miscellaneous bottles bottles of wine, spirit and liqueur. In the morning I had had been reading Glover’s “Leonidas”, Wilkie’s Wilkie’s “Epigoniad”, Lamartine’s “Pilgrimage”, Barlow’s “Columbiad”, Tuckermann’s “Sicily”, and Griswold’s “Curiosities” ; I am willing to confess, therefore, that I now felt a little stupid.
Ý tưởng: Đầu tiên ta phải xem có các từ nào lặp lại không. Sử dụng \1 để tìm các từ lặp, kết hợp \b để là bắt đầu và kết thúc của 1 từ.
=> Văn phong khi tìm từ lặp sẽ là: bắt đầu 1 từ, từ bất kì, dấu cách, từ tiếp theo có phải từ đó không, kết thúc 1 từ.
=> Biểu thức regex:\b(.+)\s(\1)\b
Thay thế thì easy quá, thay thế $1 là được :D
3.9. Digit commas formatting
Bài toán format dân số các quốc gia1
2
3
4
5
6
7
8
9
10
11Ten Countries with the Highest Population:
1 China 1361220000
2 India 1236800000
3 United States 317121000
4 Indonesia 237641326
5 Brazil 201032714
6 Pakistan 184872000
7 Nigeria 173615000
8 Bangladesh 152518015
9 Russia 143600000
10 Japan 127290000
Về dạng1
2
3
4
5
6
7
8
9
10
11Ten Countries with the Highest Population:
1 China 1,361,220,000
2 India 1,236,800,000
3 United States 317,121,000
4 Indonesia 237,641,326
5 Brazil 201,032,714
6 Pakistan 184,872,000
7 Nigeria 173,615,000
8 Bangladesh 152,518,015
9 Russia 143,600,000
10 Japan 127,290,000
Ý tưởng:
- Chúng ta sẽ lấy ra những số mà theo sau nó là 3,6,9… chữ số và kí tự kết thúc là kết thúc từ (kiểu tính từ cuối từ lên)=> sử dụng lookahead
- Thay thế nó bởi nó và dấu , là được :D
Kết quả:
Replace:\d(?=(\d{3})+\b) with $1,
3.13. Validate AM/PM time format
Valid and invalid time:
00:15 AM
7:40 AM
8:51 AM8:61 AM
09:59
1:00 PM
2:00 PM19:34 PM
Ý tưởng: cái khó ở đây là viết kí tự đại diện cho giờ. Giờ có thể là 1 số hoặc 2 số, nhỏ hơn 12. Ta có thể dùng ? để làm việc này
The solution is:\b(0?\d|1[0-2]):[0-5]\d (AM|PM)
3.17. Validate 32 or 24 bit hexadecimal colors
White:
#ffffff,#ffffffffBlack:
#000000#000000ffSemitrnasparent green:
#00ff0088Nonhexadecimal: #00ffhh #agaeffe0
Wrong bytes count:#00ff00f #fffff #888888fff
Để sử dụng độ dài chính xác của 1 chuỗi, sử dụng {n}
The solution is: #(([0-9a-f]{6})|([0-9a-f]{8}))\b
3.21. Strings not containing word
Tìm kiếm tất cả các công thức không chứa từ ‘chocolate’
Cake 1: sugar, flour, cocoa powder, baking powder, baking soda, salt, eggs, milk, vegetable oil, vanilla extract, chocolate chips
Cake 2: cream cheese, sugar, vanilla extract, crescent rolls, cinnamon, butter, honeyCake 3: dark chocolate cake mix, instant chocolate pudding mix, sour cream, eggs, vegetable oil, coffee liqueur
Cake 4: flour, baking powder, salt, cinnamon, butter, sugar, egg, vanilla extract, milk, chopped walnuts
Cake 5: gingersnap cookies, chopped pecans, butter, cream cheese, sugar, vanilla extract, eggs, canned pumpkin, cinnamonCake 6: flour, baking soda, sea salt, butter, white sugar, brown sugar, eggs, vanilla extract, chocolate chips, canola oil
Cake 7: wafers, cream cheese, sugar, eggs, vanilla extract, cherry pie filling
Ý tưởng:
- Sử dụng lookahead (?!) để kiểm tra thôi
- Vì nó là kiểm tra câu, phải sử dụng ^ và $
The solution is: ^(.(?!chocolate))*$
Tổng kết
- Nếu kiểm tra cả một câu, một từ có phù hợp regex, sử dụng
^và$hoặc\b, toàn nếu chỉ muốn lấy chuỗi thỏa mãn regex thì không cần. - Các kí tự lặp lại (Symbol repetition) đại diện cho các kí tự tiếp theo, số lượng các kí tự tiếp theo là bao nhiêu thì phụ thuộc bạn dùng kí tự nào.
*,\?,+hay{}bản chất như nhau hết (ví dụ như*tương đươngx{0,}) Lookaheads(?=minh),(?!minh)khá hay, nó cho phép bạn check được cả sau 1 từ có chuỗi hay không có chuỗi con nào đó. Nhìn nguy hiểm vậy thôi chứa(?!abcdef)cũng chỉ đại diện cho 1 kí tự, nó khác với regex a ở chỗ check thêm sau a không được chứa chuỗiabcdef- Match 0 hay lookaheads không nên đứng độc lập
(\d*, (?!abc)\*)vì nó bắt cả kí tự rỗng (đỏ đỏ :v)) nó cần kết hợp thêm các kí tự khác để bắt chuẩn hơn(\d\d* hay minh(?!abc)*) \1, \2 và $1, $2, (?:expression)bạn có thể nhắc lại chúng??- Bạn có thể định nghĩa regex qua 2 cách: các kí tự được phép sử dụng
[abc]hoặc các kí tự không được phép sử dụng[^abc], tùy từng trường hợp mà sử dụng cho phù hợp nhé.
Tài liệu tham khảo:
[Regex] Regex Cheatsheet and Practice
http://yoursite.com/2019/12/29/Regex-Regex-Cheatsheet-and-Practice/