[Clean code] Chapter 8: Boundaries
Chúng ta hiếm khi kiểm soát tất cả các phần mềm trong hệ thống của mình. Đôi khi chúng tôi mua gói (packages) của bên thứ ba hoặc sử dụng mã nguồn mở (open source). Những lần khác, chúng tôi phụ thuộc vào các nhóm trong công ty để tạo ra các thành phần hoặc hệ thống con. Bằng cách nào đó, chúng ta phải tích hợp code ngoài này với code riêng của chúng ta một cách rõ ràng. Trong chương này, chúng ta xem xét các thực hành và kỹ thuật để giữ các ranh giới của phần mềm của chúng ta sạch sẽ.
Using Third-Party Code
Có một sự căng thẳng mặc nhiên giữa người cung cấp interface và người sử dụng interface. Các nhà cung cấp third-party packages và framework cố gắng mang lại khả năng ứng dụng rộng rãi để họ có thể hoạt động trong nhiều môi trường và thu hút nhiều đối tượng. Mặt khác, người dùng muốn có một interface tập trung vào các nhu cầu cụ thể của họ. Sự căng thẳng này có thể gây ra vấn đề ở ranh giới của hệ thống.
Hãy nhìn vào java.util.Map như 1 ví dụ. Như bạn có thể thấy phần 8-1, Map có rất rất nhiều interface với đầy đủ các chức năng. Chắc chắn sức mạnh và tính linh hoạt này là hữu ích, nhưng nó cũng có thể là một trách nhiệm. Ví dụ: ứng dụng của chúng tôi có thể xây dựng Map và chuyển nó đi khắp nơi. Ý định của chúng tôi có thể là không ai trong số những người nhận Map xóa bất kỳ thứ gì trong bản đồ. Nhưng ngay ở đầu danh sách là phương thức clear(). Bất kỳ người sử dụng Map nào cũng có quyền xóa nó. Hoặc có thể quy ước thiết kế của chúng tôi là chỉ các loại đối tượng cụ thể mới có thể được lưu trữ trong Map, nhưng Map không ràng buộc một cách đáng tin cậy các loại đối tượng được đặt bên trong chúng. Bất kỳ người dùng nào được xác định đều có thể thêm các mục thuộc bất kỳ loại nào vào bất kỳ Map nào.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// The methods of Map
• clear() void – Map
• containsKey(Object key) boolean – Map
• containsValue(Object value) boolean – Map
• entrySet() Set – Map
• equals(Object o) boolean – Map
• get(Object key) Object – Map
• getClass() Class<? extends Object> – Object
• hashCode() int – Map
• isEmpty() boolean – Map
• keySet() Set – Map
• notify() void – Object
• notifyAll() void – Object
• put(Object key, Object value) Object – Map
• putAll(Map t) void – Map
• remove(Object key) Object – Map
• size() int – Map
• toString() String – Object
• values() Collection – Map
• wait() void – Object
• wait(long timeout) void – Object
• wait(long timeout, int nanos) void – Object
Nếu ứng dụng cần một Map của Sensors, bạn phải tìm các sensors theo code sau:1
Map sensors = new HashMap();
Sau đó khi một đoạn code cần truy cập sensor, bạn sẽ nhìn thấy code:1
Sensor s = (Sensor) sensors.get(sensorId );
Chúng tôi không chỉ nhìn thấy nó một lần mà nhiều lần trong source code. Ứng dụng của mã này có trách nhiệm lấy một Object từ Map và truyền nó đến đúng loại. Điều này hoạt động, nhưng nó không phải là clean code. Ngoài ra, mã này không kể câu chuyện của nó tốt như nó có thể. Khả năng đọc của mã này có thể được cải thiện đáng kể bằng cách sử dụng get():1
2
3Map<Sensor> sensors = new HashMap<Sensor>();
...
Sensor s = sensors.get(sensorId );
Tuy nhiên, điều này không giải quyết được vấn đề rằng Map<Sensor> cung cấp nhiều khả năng hơn thứ chúng ta cần và muốn.
Truyền một instance của Map<Sensor> xung quanh hệ thống có nghĩa là sẽ có rất nhiều chỗ cần sửa nếu interface của Map thay đổi. Bạn có thể nghĩ rằng một sự thay đổi như vậy là khó xảy ra, nhưng hãy nhớ rằng nó đã thay đổi khi hỗ trợ generic được thêm vào trong Java 5. Thật vậy, chúng tôi đã thấy các hệ thống bị hạn chế sử dụng generics vì mức độ lớn của những thay đổi cần thiết để bù đắp cho tự do sử dụng Maps.
Một cách tốt hơn để sử dụng Map có thể như sau. Không một người sử dụng Sensors nào muốn quan tâm đến liệu generics này có được sử dụng hay không. Sự lựa chọn trở thành (Và luôn luôn nên là) một sự thực thi chi tiết1
2
3
4
5
6
7
8
9public class Sensors {
private Map sensors = new HashMap();
public Sensor getById(String id) {
return (Sensor) sensors.get(id);
}
// snip
}
Interface ranh giới Map đã bị ẩn đi. Nó có thể phát triển với rất ít tác động đến phần còn lại của ứng dụng. Việc sử dụng generic không còn là một vấn đề lớn vì quá trình truyền và quản lý kiểu được xử lý bên trong lớp Sensors.
Interface này cũng được điều chỉnh và hạn chế để đáp ứng nhu cầu của ứng dụng. Nó dẫn đến mã dễ hiểu hơn và khó sử dụng sai hơn. Lớp Sensors có thể thực thi các quy tắc design và business.
Chúng tôi không gợi ý tất cả sử dụng Map đều đóng gói theo cách này. Chúng tôi đang muốn đưa ra lời khuyên với bạn là đừng truyền Maps (hoặc 1 vài interface ranh giới) quanh hệ thống. Nếu bạn sử dụng một interface ranh giới như Map, hãy giữ nó trong một class hoặc một thứ tương tự class, nơi mà nó được sử dụng. Tránh việc trả về nó hoặc chấp nhận nó như một đối số của public APIs.
Đừng sử dụng methods, code bên thứ 3 trực tiếp quanh hệ thống, hãy “bọc” chúng lại!
Exploring and Learning Boundaries
Code của bên thứ ba giúp chúng ta nhận được nhiều chức năng hơn được phân phối trong thời gian ngắn hơn. Chúng ta phải bắt đầu từ đâu khi muốn sử dụng một số gói của bên thứ ba? Công việc của chúng ta không phải là kiểm tra mã của bên thứ ba, nhưng chúng ta có thể có lợi nhất khi viết tests cho mã của bên thứ ba mà chúng tôi sử dụng.
Giả sử chúng ta không rõ cách sử dụng thư viện bên thứ ba của. Chúng ta có thể dành một hoặc hai ngày (hoặc nhiều hơn) để đọc tài liệu và quyết định cách sẽ sử dụng nó. Sau đó, chúng ta có thể viết code của mình để sử dụng code của bên thứ ba và xem liệu nó có đúng như những gì chúng tôi nghĩ hay không. Chúng tôi sẽ không ngạc nhiên khi thấy mình bị sa lầy trong các bugs và cố gắng tìm hiểu xem lỗi chúng tôi đang gặp phải là trong code của chúng ta hay code của họ.
Học code của bên thứ 3 là khó. Tích hợp code bên thứ 3 cũng khó. Làm cả 2 cùng 1 lúc thì là khó nhân đôi :v. Điều gì sẽ xảy ra nếu chúng tôi thực hiện một cách tiếp cận khác? Thay vì thử nghiệm và thử những thứ mới trong code của mình, chúng tôi có thể viết một số tests để khám phá sự hiểu biết về mã của bên thứ ba. Jim Newkirk gọi những bài tests như vậy là bài kiểm tra học tập (learning tests)
Thay vì thử nghiệm và thử những thứ mới trong code của mình, chúng tôi có thể viết một số tests để khám phá sự hiểu biết về mã của bên thứ ba. Jim Newkirk gọi những bài tests như vậy là bài kiểm tra học tập (learning tests)
Trong learning tests, chúng ta gọi các API bên thứ 3 vì chúng ta mong đợi sử dụng nó trong ứng dụng của mình. Về cơ bản, chúng ta đang thực hiện các thử nghiệm được kiểm soát để kiểm tra sự hiểu biết về API đó. Các tests tập trung vào những gì chúng tôi muốn từ API.
Learning log4j
Hãy nói chúng ta muốn sử dụng apache log4j package hơn việc tự tạo custom logger. Chúng ta download nó và đọc hướng dẫn. Không tốn nhiều thời gian đọc, chúng ta viết test case đầu tiên, ghi “hello” ra console1
2
3
4
public void testLogCreate() {
Logger logger = Logger.getLogger("MyLogger");
logger.info("hello"); }
Khi chúng ta chạy nó logger sẽ sinh ra lỗi để nói rằng chúng ta cần một thứ gì đó gọi là một Appender. Đọc thêm 1 lúc nữa, chúng ta tìm thấy có một ConsoleAppender. Do đó chúng ta tạo một ConsoleAppender và đã mở khoá được bí mật trong log:1
2
3
4
5
6
7
public void testLogAddAppender() {
Logger logger = Logger.getLogger("MyLogger");
ConsoleAppender appender = new ConsoleAppender();
logger.addAppender(appender);
logger.info("hello");
}
Đến lúc này chúng ta nhận thấy Appender không có output. Kỳ lạ — có vẻ hợp lý khi nó có một cái. Sau một chút trợ giúp từ Google, chúng tôi thử những cách sau:1
2
3
4
5
6
7
8
9
public void testLogAddAppender() {
Logger logger = Logger.getLogger("MyLogger");
logger.removeAllAppenders();
logger.addAppender(new ConsoleAppender(
new PatternLayout("%p %t %m%n"),
ConsoleAppender.SYSTEM_OUT));
logger.info("hello");
}
Nó đã hoạt động. Một message lỗi bao gồm “hello” đã hiển thị console!
Điều thú vị là khi chúng ta loại bỏ đối số ConsoleAppender.SystemOut, chúng ta thấy rằng “hello” vẫn được in. Nhưng khi chúng ta lấy ra PatternLayout, một lần nữa nó lại gặp phải vấn đề thiếu một luồng đầu ra. Đây là hành vi rất kỳ lạ.
Đọc lại một chút cẩn thận tài liệu, chúng tôi thấy hàm tạo ConsoleAppender mặc định là “chưa được config” mà dường như không quá rõ ràng hoặc hữu ích. Điều này giống như một lỗi, hoặc ít nhất là sự không nhất quán, trong log4j.
Đọc và test thêm một chút, chúng tôi đã có kết quả như dưới. Chúng tôi đã khám phá ra rất nhiều điều về cách log4j hoạt động và chúng tôi đã mã hóa kiến thức đó thành một tập hợp unit tests đơn giản.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public class LogTest {
private Logger logger;
public void initialize() {
logger = Logger.getLogger("logger");
logger.removeAllAppenders();
Logger.getRootLogger().removeAllAppenders();
}
public void basicLogger() {
BasicConfigurator.configure();
logger.info("basicLogger");
}
public void addAppenderWithStream() {
logger.addAppender(new ConsoleAppender(
new PatternLayout("%p %t %m%n"),
ConsoleAppender.SYSTEM_OUT
));
logger.info("addAppenderWithStream");
}
public void addAppenderWithoutStream() {
logger.addAppender(new ConsoleAppender( new PatternLayout("%p %t %m%n")));
logger.info("addAppenderWithoutStream");
}
}
Bây giờ chúng ta biết cách khởi tạo trình ghi log đơn giản và đóng gói kiến thức đó vào lớp Logger của riêng mình để phần còn lại của ứng dụng được tách biệt khỏi giao diện ranh giới log4j.
Learning Tests Are Better Than Free
Các learning tests kết thúc không tốn kém gì. Dù sao thì chúng tôi cũng phải học API và viết những tests đó là một cách dễ dàng và riêng biệt để có được kiến thức đó. Các learning tests là những thí nghiệm chính xác giúp nâng cao hiểu biết của chúng tôi.
Không chỉ miễn phí các learning tests, chúng còn rất có lợi. Khi có các bản phát hành mới của gói bên thứ ba, chúng tôi sẽ chạy các test để xem liệu có sự khác biệt về hành vi hay không.
Learning tests xác nhận các package bên thứ 3 hoạt động như cách chúng ta mong đợi. Sau khi được tích hợp, không có gì đảm bảo rằng code của bên thứ ba sẽ vẫn tương thích với nhu cầu của chúng ta. Các tác giả ban đầu (bên thứ 3) sẽ có áp lực để thay đổi mã của họ để đáp ứng nhu cầu mới của họ. Họ sẽ sửa lỗi và bổ sung các khả năng mới. Với mỗi lần phát hành đều có rủi ro mới. Nếu gói của bên thứ ba thay đổi theo một cách nào đó không tương thích với các test của chúng ta, chúng ta sẽ tìm hiểu ngay.
Cho dù bạn có cần kiến thức được cung cấp bởi các bài kiểm tra học tập hay không, một ranh giới rõ ràng sẽ được hỗ trợ bởi một tập hợp các tests gửi đi thực hiện interface giống như cách code thực tế thực hiện. Nếu không có các thử nghiệm ranh giới (boundary tests) này để dễ dàng di chuyển, chúng tôi có thể bị cám dỗ ở lại với phiên bản cũ lâu hơn chúng ta nên làm.
Using Code That Does Not Yet Exist
Có một loại ranh giới khác, một loại ranh giới ngăn cách cái đã biết và cái chưa biết. Thường có những chỗ trong mã mà kiến thức của chúng ta dường như còn thiếu. Đôi khi những gì ở phía bên kia của ranh giới là không thể biết được (ít nhất là ngay bây giờ). Đôi khi chúng ta chọn không nhìn xa hơn ranh giới.
Vài năm trước, tôi là thành viên của nhóm phát triển phần mềm cho hệ thống thông tin liên lạc qua đài phát thanh. Có một hệ thống con, Transmitter, mà chúng tôi ít biết về nó, và những người chịu trách nhiệm về hệ thống con chưa đến mức xác định interface của chúng. Chúng tôi không muốn bị block, vì vậy chúng tôi đã bắt đầu công việc của mình từ phần chưa biết của mã.
Chúng tôi đã có một ý tưởng khá tốt về nơi thế giới của chúng tôi kết thúc và thế giới mới bắt đầu. Khi chúng tôi làm việc, đôi khi chúng tôi va chạm với ranh giới này. Mặc dù sương mù và những đám mây của sự thiếu hiểu biết đã che khuất tầm nhìn của chúng tôi bên ngoài ranh giới, công việc của chúng tôi đã giúp chúng tôi nhận thức được chúng tôi muốn giao diện ranh giới là gì. Chúng tôi muốn nói với transmitter gì đó như thế này:
Key the transmitter on the provided frequency and emit an analog representation of the data coming from this stream.
Chìa khoá của máy phát trên tần số (Key the transmitter) được cung cấp và phát ra một biểu diễn tương tự của dữ liệu đến từ luồng này.
Chúng tôi không biết điều đó sẽ được thực hiện như thế nào vì API chưa được thiết kế. Vì vậy, chúng tôi quyết định làm việc chi tiết sau.
Để tránh bị block, chúng tôi đã xác định interface của riêng mình. Chúng tôi gọi nó là thứ gì đó hấp dẫn, như Transmitter. Chúng tôi đã cung cấp cho nó một phương pháp gọi là truyền lấy tần số và luồng dữ liệu. Đây là interface chúng tôi ước chúng tôi có.
Một điều tốt khi viết giao diện mà chúng tôi mong muốn là nó nằm trong tầm kiểm soát của chúng tôi. Điều này giúp giữ cho mã khách hàng dễ đọc hơn và tập trung vào những gì nó đang cố gắng hoàn thành.
Hình 8-2 bạn có thể thấy chúng tôi đã cách ly CommunicationsController class từ transmitter API (nằm ngoài tầm kiểm soát của chúng tôi và không xác định). Bằng cách sử dụng interface ứng dụng cụ thể của riêng chúng tôi, chúng tôi đã giữ cho code CommunicationsController của mình sạch sẽ và dễ hiểu. Khi API bộ truyền được xác định, chúng tôi đã viết TransmitterAdapter để thu hẹp khoảng cách. ADAPTOR2 đã đóng gói tương tác với API và cung cấp một nơi duy nhất để thay đổi khi API phát triển.
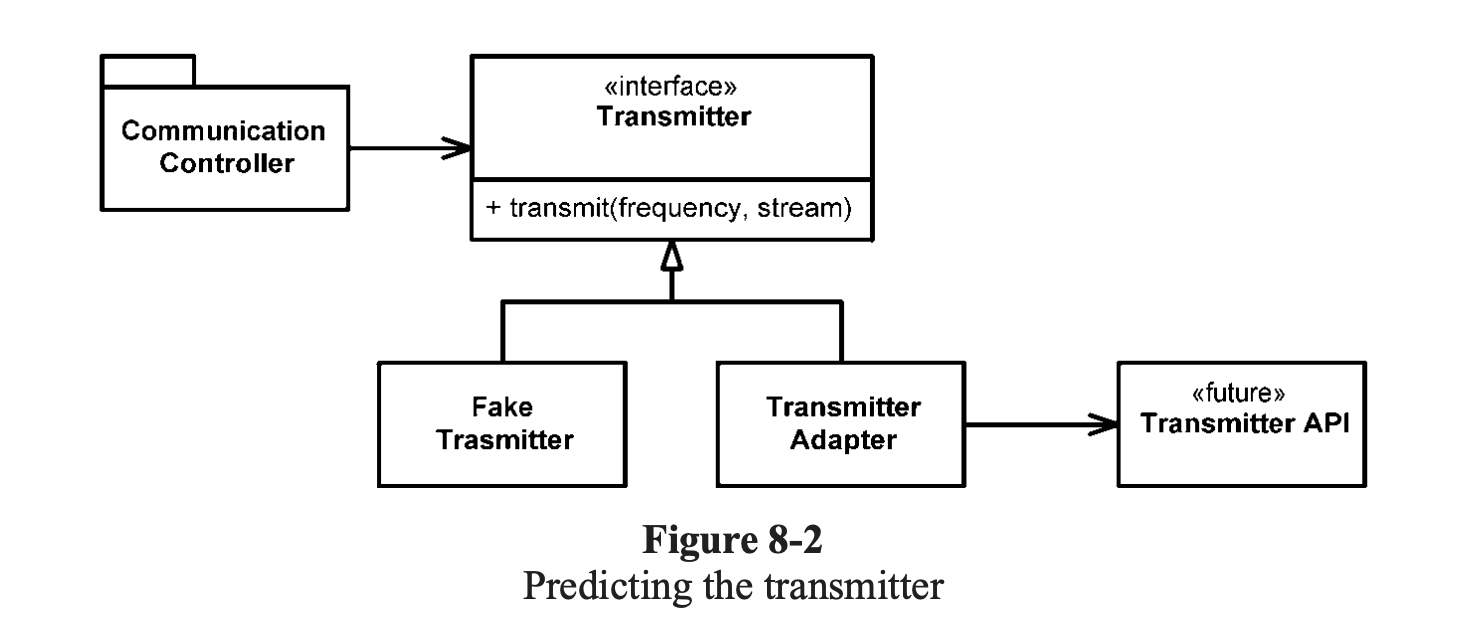
Thiết kế này cũng cung cấp cho chúng tôi một đường may rất thuận tiện trong code để kiểm tra. Sử dụng FakeTransmitter phù hợp, chúng ta có thể kiểm tra các lớp CommunicationsController. Chúng tôi cũng có thể tạo các bài kiểm tra ranh giới sau khi chúng tôi có TransmitterAPI để đảm bảo rằng chúng tôi đang sử dụng API một cách chính xác.
Clean Boundaries
Những điều thú vị xảy ra ở ranh giới. Thay đổi là một trong những điều đó. Các thiết kế phần mềm tốt có thể đáp ứng sự thay đổi mà không cần đầu tư lớn và làm lại. Khi chúng tôi sử dụng code ngoài tầm kiểm soát, chúng tôi phải đặc biệt lưu ý để bảo vệ khoản đầu tư của mình và đảm bảo việc thay đổi trong tương lai không quá tốn kém.
Code tại các ranh giới cần có sự phân tách rõ ràng và các tests xác định các kỳ vọng. Chúng ta nên tránh để quá nhiều code của mình biết về các thông tin chi tiết của bên thứ ba. Tốt hơn là phụ thuộc vào thứ bạn kiểm soát hơn là phụ thuộc vào thứ bạn không kiểm soát, vì nó sẽ kiểm soát bạn.
Code tại các ranh giới cần có sự phân tách rõ ràng và các tests xác định các kỳ vọng. Chúng ta nên tránh để quá nhiều code của mình biết về các thông tin chi tiết của bên thứ ba. Tốt hơn là phụ thuộc vào thứ bạn kiểm soát hơn là phụ thuộc vào thứ bạn không kiểm soát, vì nó sẽ kiểm soát bạn.
Chúng tôi quản lý ranh giới của bên thứ ba bằng cách có rất ít vị trí trong code đề cập đến họ. Chúng tôi có thể bọc chúng như khi chúng tôi đã làm với Map hoặc chúng tôi có thể sử dụng một ADAPTER để chuyển đổi từ interface hoàn hảo của chúng ta sang interface đã được cung cấp. Dù bằng cách nào thì code của chúng tôi cũng nói với chúng tôi tốt hơn, thúc đẩy việc sử dụng nhất quán nội bộ trên toàn bộ ranh giới và có ít điểm bảo trì hơn khi mã của bên thứ ba thay đổi.
Bibliography
[BeckTDD]: Test Driven Development, Kent Beck, Addison-Wesley, 2003.
[GOF]: Design Patterns: Elements of Reusable Object Oriented Software, Gamma et al., Addison-Wesley, 1996.
[WELC]: Working Effectively with Legacy Code, Addison-Wesley, 2004.
[Clean code] Chapter 8: Boundaries
http://yoursite.com/2024/08/17/Clean-code-Chapter-8-Boundaries/